Imaginez que vous livrez un produit IA qui réussit chaque démo. Votre équipe le teste en profondeur avant le lancement, et les sorties semblent excellentes, alors vous livrez avec confiance. Cependant, deux semaines plus tard, un client vous envoie une capture d’écran d’une réponse factuellement erronée, affirmée avec assurance, et en totale contradiction avec ce que le même produit avait dit la veille. Cela pourrait être un coup sérieux à votre réputation, et vous ne pouvez absolument pas vous permettre de perdre la confiance de vos clients.
Maintenant, vos ingénieurs fouillent le code source et ne trouvent rien d’anormal. Le code n’a pas du tout changé, mais le modèle si, discrètement, du côté du fournisseur. Le pire de tout est qu’il n’y a aucune entrée de journal des modifications que quiconque aurait su chercher.
Ce scénario se joue dans les équipes de produits IA chaque jour en 2025, et même des tests IA approfondis ne vous permettent d’aller que jusqu’à un certain point pour le prévenir. C’est précisément pourquoi une nouvelle discipline opérationnelle appelée EvalOps émerge rapidement parmi les équipes qui construisent de véritables produits IA.
Dans cet article, les experts en tests de QAwerk expliqueront ce qu’est EvalOps, pourquoi il a émergé maintenant, et à quoi cela ressemble quand une équipe le met en pratique. Si vous avez entendu ce terme lors d’une conférence ou d’un argumentaire commercial et que vous souhaitez une explication en langage simple ne supposant pas que vous ayez une formation en apprentissage automatique, vous êtes au bon endroit.
Qu’est-ce qu’EvalOps ?
Commençons par définir exactement de quoi nous parlons. Pour le dire simplement, EvalOps est la pratique consistant à traiter l’évaluation des sorties IA comme une discipline opérationnelle continue de niveau production, plutôt que comme une vérification de qualité pré-lancement que l’on effectue une seule fois avant la mise en service.
Vous pourriez remarquer que le nom suit un schéma familier utilisé par l’industrie logicielle. DevOps a transformé le déploiement logiciel d’un événement de version trimestrielle en une pratique continue et automatisée. MLOps a fait de même pour la gestion du cycle de vie des modèles d’apprentissage automatique. EvalOps fait de même pour l’évaluation du déploiement et des opérations IA, transformant quelque chose qui était autrefois une porte à passage unique en un système continu qui continue de fonctionner longtemps après le lancement.
Cependant, il y a une clarification importante à apporter dès le début. Vous rencontrerez le terme « EvalOps » utilisé à la fois comme nom de produit d’un fournisseur et comme nom de cette discipline opérationnelle plus large. Cet article porte sur une discipline que toute équipe peut adopter, quels que soient les outils qu’elle choisit d’utiliser.
La manière la plus simple de comprendre EvalOps est de le comparer à l’assurance qualité (QA) logicielle traditionnelle. Le QA conventionnel repose sur une hypothèse rassurante : écrire le code, définir les sorties attendues, exécuter les tests et livrer quand les tests passent. Cela signifie que la même entrée produira toujours la même sortie, de sorte que vous pouvez écrire une suite de tests une seule fois et lui faire confiance indéfiniment. Cependant, cette hypothèse ne tient tout simplement pas pour les produits IA, et EvalOps est la discipline qui comble ce manque.
Pourquoi les tests IA traditionnels sont insuffisants : Le plaidoyer pour EvalOps
EvalOps existe en tant que concept en 2025, non pas parce que les produits IA sont nouveaux, mais parce que les tests traditionnels s’effondrent fondamentalement quand votre produit est construit sur un grand modèle de langage (LLM). De plus, cette industrie n’a atteint que récemment l’échelle à laquelle cet effondrement a de réelles conséquences commerciales.
Selon le rapport 2025 de McKinsey sur l’état de l’IA, 88 % des organisations utilisent désormais l’IA dans au moins une fonction métier. Cependant, seulement 39 % d’entre elles rapportent un impact financier au niveau enterprise. Cela signifie que le fossé entre adoption et valeur est énorme et qu’il ne s’agit pas principalement d’un problème de qualité du modèle. Il est souvent causé par des opérations et des mesures inadaptées, avec l’évaluation au centre.
La raison est que les LLM sont non-déterministes par conception. Cela signifie que le même prompt, soumis deux fois au même modèle avec la même configuration, peut retourner deux réponses significativement différentes. Ce n’est pas un bogue mais une caractéristique architecturale de la façon dont ces systèmes génèrent du texte. Cependant, cela crée un problème de test sans véritable précédent dans le développement logiciel conventionnel, car les règles sur lesquelles votre suite de tests a été construite ne s’appliquent plus.
Trois modes d’échec spécifiques rendent le QA traditionnel insuffisant pour les produits IA, et chacun mérite d’être compris en ses propres termes.
- Hallucinations
Les hallucinations IA sont le mode d’échec le plus largement discuté. Un modèle génère une réponse confiante, fluide, grammaticalement correcte qui est factuellement erronée. Il ne signale pas l’incertitude ni ne renvoie d’erreur. La sortie semble parfaitement correcte et est pourtant fausse, et sans système de notation vérifiant activement l’exactitude factuelle, cette sortie atteint vos utilisateurs sans rien pour l’arrêter. - Dérive
La dérive du modèle est plus silencieuse et souvent plus dommageable à long terme. Les fournisseurs de LLM mettent continuellement à jour leur infrastructure, de sorte que votre prompt qui obtenait un bon score en mars peut obtenir un score très différent en juillet parce que le modèle sous-jacent a été mis à jour, réentraîné sur de nouvelles données ou autrement modifié. Sans système surveillant activement la qualité des sorties dans le temps, vous ne saurez pas que c’est en train d’arriver jusqu’à ce qu’un utilisateur vous le dise. - Sensibilité au contexte
Ce mode signifie que la qualité de la sortie dépend profondément de facteurs que votre suite de tests pré-lancement n’a jamais couverts. Ceux-ci peuvent inclure la formulation spécifique choisie par un vrai utilisateur, l’historique de conversation qui précède la requête, les documents récupérés depuis votre base de données, ou les cas limites qui n’apparaissent qu’avec un volume de trafic de production complet. Une suite de tests qui passe 200 exemples soigneusement sélectionnés avant le lancement vous donne une confiance très limitée quant au comportement que vos utilisateurs réels rencontreront en pratique.
Pour les équipes construisant des flux de travail IA autonomes ou multi-étapes, les risques cachés du déploiement d’agents IA méritent une attention particulière, car dans de telles architectures, les échecs ont tendance à être en cascade plutôt que de se produire proprement et visiblement.
L’analogie qui l’illustre le plus clairement est celle qui nous a donné DevOps en premier lieu. DevOps a émergé parce que « déployer une fois et maintenir » ne fonctionnait pas pour le logiciel à grande échelle. EvalOps émerge exactement pour la même raison : parce que « tester une fois et livrer » ne fonctionne pas non plus pour l’IA à grande échelle.
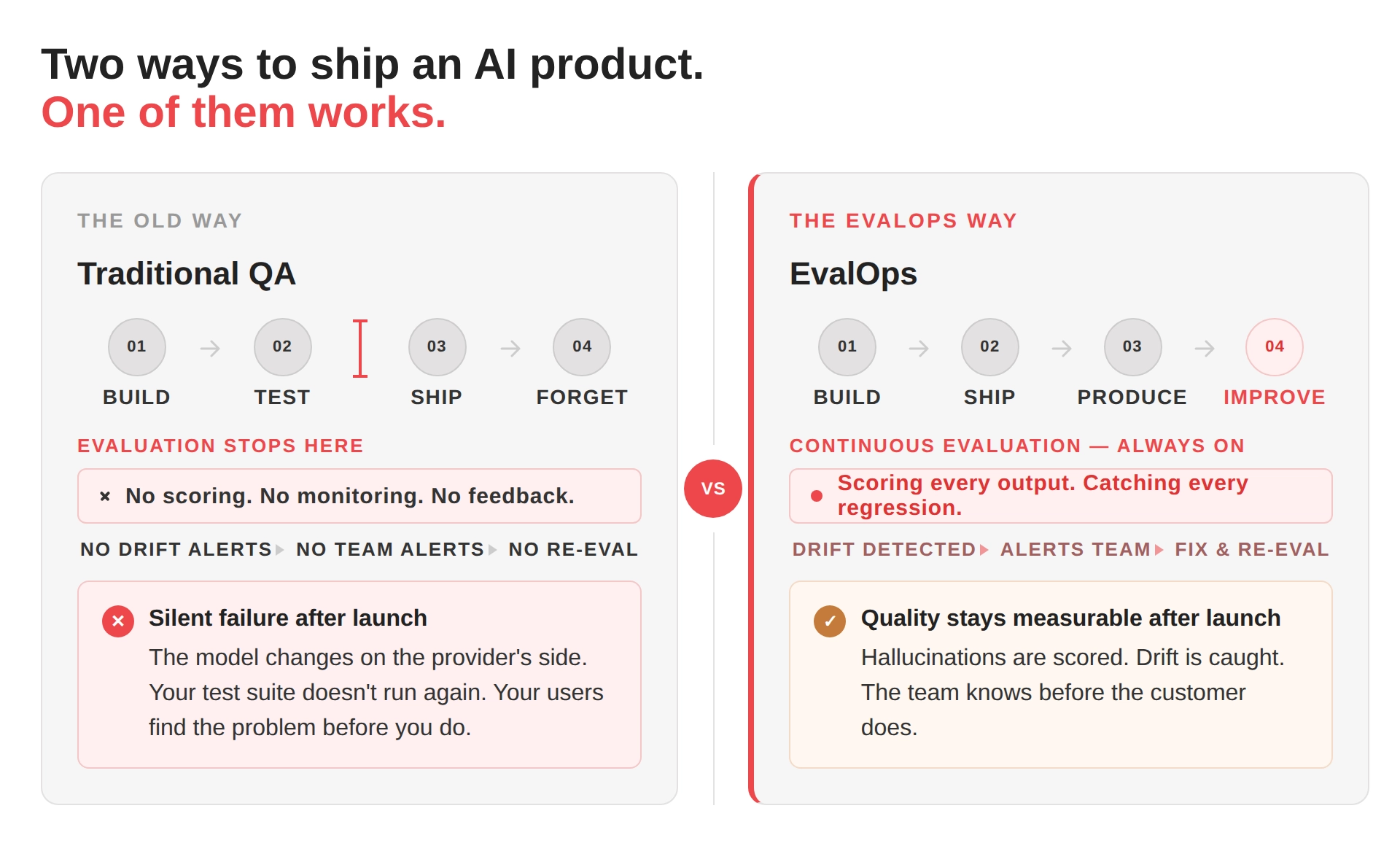
EvalOps vs LLMOps : Quelle est la différence ?
Vous verrez souvent EvalOps discuté aux côtés de LLMOps, et les deux sont réellement liés, mais ce ne sont pas la même chose, et la différence est importante.
- Qu’est-ce que LLMOps ?
LLMOps est le processus qui couvre l’ensemble du cycle de vie opérationnel d’un produit basé sur LLM, y compris la sélection du modèle, l’ingénierie des prompts et leur versionnage, l’infrastructure de déploiement, la gestion des coûts, l’optimisation de la latence et la surveillance en production. Vous pouvez le considérer comme le système d’exploitation complet pour exécuter un produit IA en production. - En quoi EvalOps diffère-t-il de LLMOps ?
EvalOps est une discipline au sein de LLMOps qui possède spécifiquement la couche d’évaluation. Ainsi, si LLMOps est l’usine, alors EvalOps est le plancher de contrôle qualité. LLMOps demande si le système fonctionne. Pendant ce temps, EvalOps demande si ce que le système produit est réellement bon.
Si vous avez besoin d’une manière plus concrète d’établir les distinctions, considérez ceci :
- LLMOps couvre : le déploiement, l’infrastructure, le versionnage, les coûts et la santé du système.
- EvalOps couvre : le scoring de qualité des sorties, la détection d’hallucinations, le suivi de la dérive, les portes de qualité dans le pipeline de publication, et la mesure continue de si votre produit IA fait ce qu’il est censé faire.
La plupart des équipes qui ont sérieusement investi dans LLMOps ont une infrastructure de déploiement et de surveillance solide en place. Un nombre surprenant d’entre elles ont un manque significatif dans la couche d’évaluation, car l’évaluation nécessite le plus de jugement de domaine et a la solution clef-en-main la moins évidente. EvalOps est la discipline qui comble ce manque.
Comment implémenter EvalOps : Quatre composantes d’un pipeline d’évaluation en production
Une fois que vous comprenez le concept EvalOps, la question pratique devient ce qu’une équipe doit réellement construire et exécuter au quotidien. Il y a quatre composantes opérationnelles qui, ensemble, constituent une pratique EvalOps fonctionnelle, et chacune repose sur la précédente.
Pipelines d’évaluation LLM
Commençons par définir qu’un pipeline d’évaluation est un harnais de test automatisé et reproductible qui :
- Exécute votre produit IA sur un jeu de données sélectionné de prompts et de sorties attendues
- Évalue les résultats par rapport à des grilles de qualité définies
- Signale les régressions avant qu’elles n’atteignent jamais la production
Pour le dire simplement, c’est la fondation sur laquelle tout le reste repose. Le mot « automatisé » joue un rôle important dans cette description. La revue manuelle ne passe tout simplement pas à l’échelle une fois que vous livrez des mises à jour régulièrement. En fait, toute pratique d’évaluation qui dépend de la revue humaine pour chaque sortie s’effondrera sous son propre poids.
De plus, les équipes qui construisent sur des architectures à génération augmentée par récupération (RAG) font face à une couche supplémentaire de complexité. C’est parce que la qualité de ce qui est récupéré et la qualité de ce qui est généré doivent toutes deux être évaluées, souvent indépendamment. Vous pouvez explorer le paysage des outils pour ce type de configuration via notre tour d’horizon des outils d’évaluation RAG. Rappelez-vous qu’un pipeline bien structuré s’exécute à chaque changement de code significatif, produit un score et donne à votre équipe un signal clair avant que quoi que ce soit ne soit livré.
Le jeu de données qui alimente ce pipeline, souvent appelé « jeu de données d’or », est une collection sélectionnée d’entrées représentatives associées à des sorties attendues validées. Il est vrai que le construire et le maintenir demande un véritable effort, mais c’est l’investissement le plus important qu’une équipe de produit IA puisse faire dans son infrastructure d’évaluation.
LLM-as-a-Judge
La revue humaine est précieuse, mais ne passe pas à l’échelle du volume de sorties qu’un système IA en production génère, parfois des milliers ou millions de réponses par jour. La pratique qui a émergé pour combler ce fossé consiste à utiliser un modèle de langage secondaire pour évaluer les sorties du système principal, une technique que l’industrie a adoptée sous le nom de LLM-en-tant-que-juge.
En pratique, un second modèle reçoit une grille d’évaluation et est invité à évaluer une réponse pour son exactitude factuelle, sa pertinence par rapport à la question, le suivi des instructions et la cohérence du ton. Il retourne un score et, dans les meilleures implémentations, une explication en langage clair de ce score. Ce n’est pas un remplacement de la revue humaine mais un multiplicateur de force. Cette approche permet à votre équipe d’appliquer le jugement humain spécifiquement aux cas limites et aux schémas d’échec que le scoring automatisé met en évidence, plutôt que de réviser manuellement chaque sortie. Comprendre comment construire des grilles d’évaluation systématiques pour cela est directement lié à comment l’évaluation de la qualité des réponses des chatbots IA fonctionne en pratique.
Portes de qualité IA dans CI/CD
C’est là qu’EvalOps cesse d’être un concept et devient une discipline avec de véritables dents opérationnelles. Les portes de qualité signifient que les scores d’évaluation deviennent des conditions de déploiement. Ainsi, si votre taux d’hallucinations sur le « jeu de données d’or » dépasse un seuil que votre équipe a convenu, la publication est bloquée automatiquement. Cela fonctionne de la même manière qu’un test unitaire échoué bloque une fusion de code.
Pour que cela fonctionne, votre équipe doit s’accorder sur les scores acceptables, ce qui nécessite le travail en amont plus difficile de définir ce que la qualité signifie réellement pour votre produit spécifique. Par exemple, un outil de recherche juridique a des seuils très différents de ceux d’un assistant d’écriture créative, et aucun outil ne peut prendre cette décision à votre place. Cependant, une fois que vous l’avez prise, vous avez transformé l’évaluation d’un audit rétrospectif en une porte de qualité prospective. C’est une posture fondamentalement différente.
Les équipes qui travaillent à travers les compromis entre les tests manuels et automatisés pour les agents IA constatent souvent que la combinaison fonctionne mieux à cette étape :
- Les portes automatisées détectent les régressions mesurables
- La revue manuelle périodique détecte les changements de qualité plus subtils que les métriques de scoring seules manquent
Parmi les méthodes d’évaluation IA disponibles pour les équipes produit, les vérifications déterministes fonctionnent bien pour les sorties structurées et la conformité aux formats. Pendant ce temps, le LLM-en-tant-que-juge fonctionne mieux pour la qualité sémantique et l’exactitude nuancée. Les pipelines les plus robustes utilisent les deux.
Détection de dérive LLM en production
La détection de dérive est la couche de surveillance en production qui suit la qualité des sorties dans le temps, pas seulement au moment d’une publication. Elle détecte ce que les portes de qualité ne peuvent pas, notamment :
- La dégradation progressive qui survient après qu’un fournisseur de modèle met discrètement à jour son infrastructure
- Les changements qui surviennent après que votre base d’utilisateurs croît et introduit de nouveaux schémas d’entrée
- Les déviations de sortie qui apparaissent après que vos données de récupération deviennent obsolètes
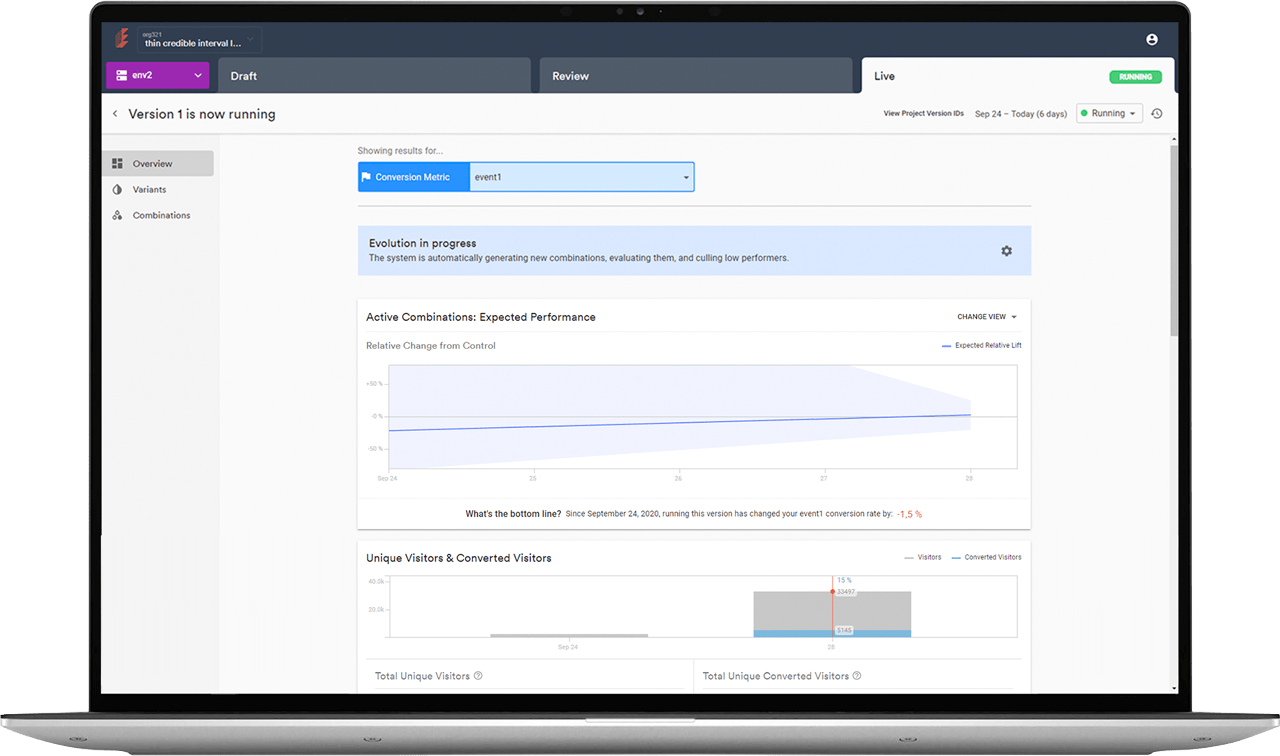
Pour visualiser l’impact de cela, considérons une équipe fintech qui livre un produit IA passant toutes les évaluations pré-lancement avec de bons scores. Cependant, six semaines plus tard, les utilisateurs commencent à signaler que les résumés sont moins précis qu’ils ne s’en souviennent. L’équipe n’a effectué aucun changement de code, donc le problème n’est pas de leur côté. Pendant ce temps, le fournisseur avait publié une mise à jour de son modèle de base. Si vous n’avez pas de système de détection de dérive échantillonnant continuellement les sorties de production et les comparant à une ligne de base de qualité, cette régression est complètement invisible jusqu’à ce que les clients la signalent.
Malheureusement, à ce stade, c’est déjà un problème de confiance plutôt qu’une tâche d’ingénierie. La recherche sur le cycle de vie des applications LLM montre que sans surveillance continue, la précision des sorties peut se dégrader significativement en quelques semaines. Les équipes n’ont souvent aucune visibilité sur le déclin jusqu’à ce qu’il devienne un problème d’expérience client.
Quels produits IA ont besoin d’EvalOps ?
Tous les produits IA ne nécessitent pas le même niveau de maturité EvalOps dès le premier jour, et c’est bien ainsi. Les questions utiles à poser pour décider si votre propre produit appartient à cette catégorie sont :
- Votre produit génère-t-il des sorties en langage naturel ouvertes ?
- Prend-il des décisions qui affectent les utilisateurs ?
- Opère-t-il dans un domaine où l’exactitude et la confiance sont importantes ?
Si votre réponse à l’une d’entre elles est « oui », vous avez besoin d’une forme d’EvalOps dès le premier déploiement en production, pas après le premier incident.
Trois catégories de produits IA font face au risque métier le plus direct en raison d’un manque d’infrastructure d’évaluation :
- Les produits IA orientés client, notamment les chatbots, les copilotes et les systèmes de recommandation, exposent les utilisateurs à des sorties dégradées dès que la qualité flanche, sans tampon interne entre l’échec et le client.
- Les outils IA internes où les erreurs affectent les décisions métier, comme l’analyse financière ou les outils de flux de travail opérationnels. Ceux-ci créent un risque, car une mauvaise réponse plausible peut se propager profondément dans un processus métier avant que quiconque ne la détecte.
- Les outils pour les environnements réglementés ou sensibles à la confiance, notamment les produits de santé, juridiques, financiers et adjacents à la conformité. Ils font face à la réalité supplémentaire que la qualité des sorties n’est pas seulement une question de qualité produit mais aussi une responsabilité potentielle.
Si vous construisez ou exploitez l’un de ces produits, consultez notre guide de test des chatbots, copilotes et systèmes de recommandation. C’est un point de départ pratique qui correspond directement à la couche d’évaluation qu’EvalOps formalise.
Vous devriez définitivement commencer petit avec EvalOps, car le paysage des outils peut sembler écrasant. Si vous êtes une équipe de cinq personnes, vous n’avez pas besoin d’une plateforme d’évaluation enterprise dès la première semaine. Ce dont vous avez besoin, c’est d’un « jeu de données d’or », d’une grille de scoring qui définit ce à quoi ressemble le bon résultat pour votre produit spécifique, et d’un accord d’équipe partagé selon lequel aucun changement qui dégrade les scores d’évaluation ne sera livré. C’est EvalOps sous sa forme minimale viable, et c’est significativement mieux que de livrer à l’instinct seul.
EvalOps et l’avenir des tests IA
Le changement fondamental qu’EvalOps représente ne concerne pas tant la technologie et les méthodes de test que la façon dont vous intégrez le QA IA dans vos opérations et votre flux de travail. L’évaluation passe d’une porte de lancement à un système continu, la mesure de qualité passe d’une revue manuelle occasionnelle à une discipline automatisée et notée qui s’exécute en permanence, et la question que l’équipe pose change de « a-t-il passé le test ? » à « quel est notre score de qualité aujourd’hui, et évolue-t-il dans la bonne direction ? »
Soyons honnêtes, si vous construisez des produits IA en 2025, ce changement n’est pas optionnel à une échelle sérieuse. Comme le rapport McKinsey sur l’état de l’IA le montre clairement, les organisations qui tirent une valeur mesurable de l’IA sont celles qui ont repensé leurs flux de travail autour d’elle, pas celles qui ont bolté des fonctionnalités IA sur des processus existants en espérant le mieux. Par conséquent, la construction d’une infrastructure d’évaluation est la partie de cette refonte que la plupart des équipes n’ont pas encore atteinte, et c’est le manque qui les rattrape en production.
C’est le manque qu’EvalOps comble, et c’est exactement le type de travail qui appartient à une pratique QA qui a évolué pour répondre aux exigences réelles des produits IA.
Si vous livrez un produit IA et n’êtes pas encore sûr de la façon dont votre couche d’évaluation est configurée, c’est la conversation à avoir plutôt tôt que tard. L’équipe de tests IA de QAwerk construit et exécute des pipelines EvalOps : conception des grilles, mise en place de l’infrastructure d’évaluation et exécution de la mesure de qualité continue, afin que votre équipe puisse rester concentrée sur la construction. Si vous êtes prêt à vous assurer que votre produit IA reste de qualité élevée, contactez-nous.
Découvrez comment nous avons aidé un outil de croissance numérique IA à augmenter la vitesse des tests de régression de 50 %.