
La plupart des échecs des systèmes RAG ne semblent pas être des échecs au premier abord. Le modèle paraît fiable. La réponse semble correcte. Mais le contexte récupéré était incorrect, ou la réponse s’écartait complètement de la source. Une étude de Stanford sur les outils RAG juridiques a révélé des taux d’hallucination allant de 17 % à 33 %, même avec une récupération d’informations améliorée.
Les équipes lancent des produits sans mesurer ce qui compte vraiment : la précision de la récupération, la cohérence et le retour d’information de la production sur l’ensemble de données. Cet article analyse huit outils d’évaluation RAG, en détaillant leur fonctionnement et le profil d’équipe auquel chacun convient le mieux. Il ne fournit pas de descriptions détaillées des fonctionnalités, mais plutôt une comparaison utile pour la conception de pipelines de tests d’IA pour nos clients.
Ce que devrait mesurer un outil d’évaluation RAG
Avant de comparer les différents cadres d’évaluation RAG, voici la liste succincte des éléments qui comptent réellement.
- Qualité de la recherche. Le système a-t-il extrait les documents pertinents ? La précision contextuelle, le rappel et le rang réciproque moyen (MRR) indiquent si le découpage en segments et l’intégration des données fonctionnent ou s’ils ne renvoient que des résultats sémantiquement similaires.
- Pertinence et fidélité. La réponse générée est-elle cohérente avec le contexte récupéré ? Une étude de 2025 sur les chatbots médicaux RAG a montré que le taux d’hallucinations chutait presque à zéro avec une récupération de données structurée, mais dépassait les 35 % sans elle.
- Pertinence de la réponse. Une réponse correcte à une requête erronée reste un échec. Les contrôles de pertinence permettent de combler cette lacune.
- Comparaison expérimentale. Pouvez-vous comparer les invites A et B, ou les modèles d’intégration X et Y, en utilisant des indicateurs de performance côte à côte ? Sans cela, l’optimisation relève de la conjecture.
- Boucles de rétroaction en production. L’évaluation hors ligne ne suffit pas. Il vous faut un cheminement depuis les interactions réelles des utilisateurs jusqu’à votre ensemble de données de test.
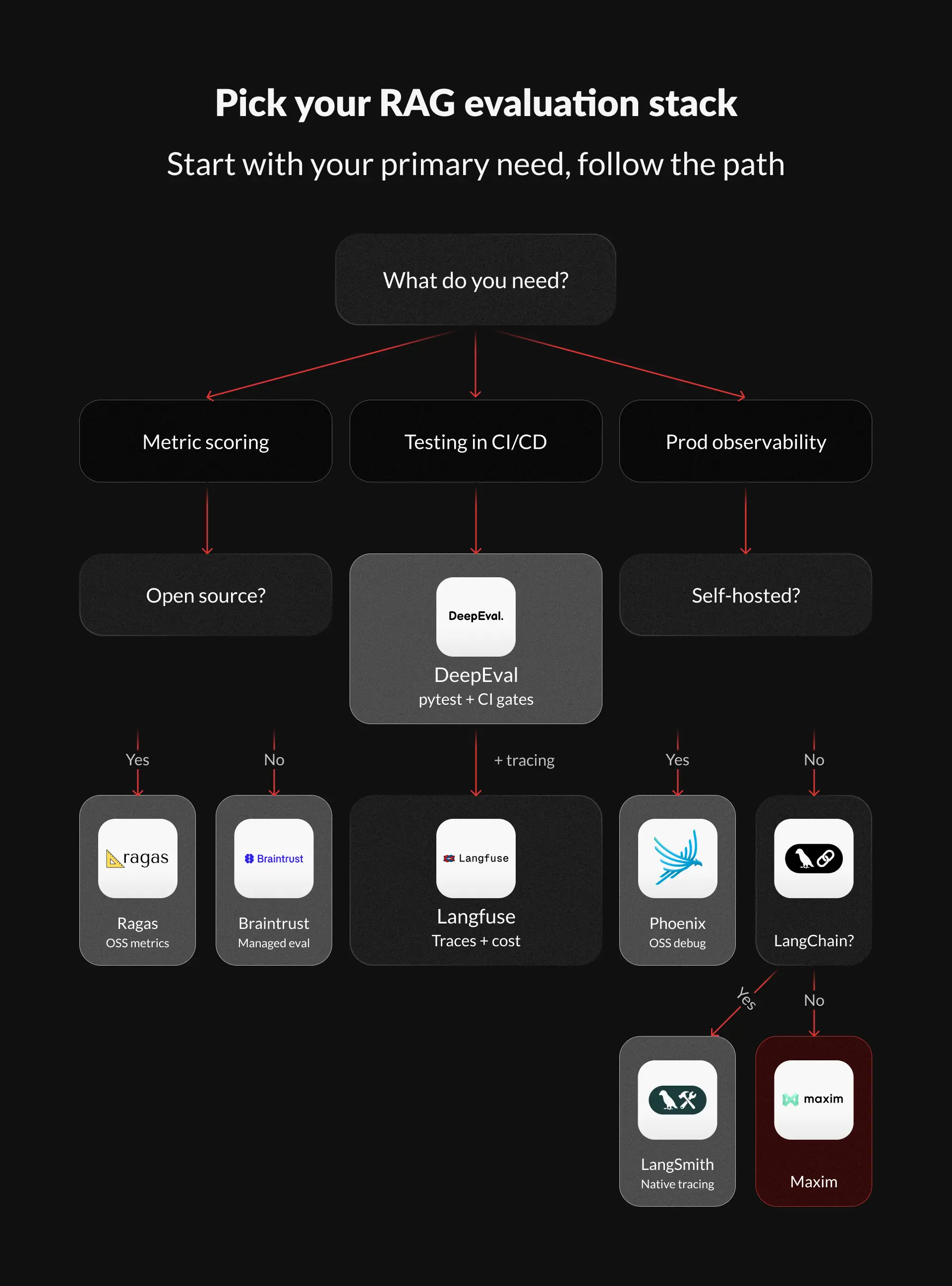
Les 8 outils d’évaluation RAG les plus importants
Nous avons organisé cette section des outils axés sur les métriques aux outils axés sur la plateforme. Cette progression reflète la façon dont la plupart des équipes évoluent réellement : commencer par le scoring, puis intégrer le traçage, les contrôles CI/CD et l’observabilité en production.
Bibliothèque Python open source pionnière dans l’évaluation RAG sans référence, utilisant des modèles linéaires logiques comme juges. Elle évalue la précision du contexte, le rappel du contexte, la fidélité et la pertinence de la réponse sans étiquettes de vérité terrain.
- Voie la plus rapide pour séparer l’évaluation de la récupération et de la génération
- S’intègre avec LangChain, LlamaIndex, Haystack et DSPy
- Le cadre d’évaluation Ragas reste le plus utilisé dans les cadres d’évaluation RAG académiques et open source.
- La génération de données de test synthétiques est intégrée
- Aucune observabilité, aucun suivi des expériences, aucun suivi de la production
- Vous obtenez des indicateurs plutôt qu’un flux de travail
Il s’agit d’un framework d’évaluation LLM open source conçu comme un plugin pytest. L’évaluation RAG de DeepEval comprend des tests unitaires, la rédaction d’assertions sur les métriques de récupération et de génération, et leur exécution dans un environnement CI/CD.
- Plus de 14 indicateurs intégrés, dont une triade RAG dédiée
- Indicateurs explicites assortis de suggestions d’amélioration
- Compatible CI/CD avec contrôles qualité sur les demandes de fusion
- Cible uniquement les équipes d’ingénierie, avec un soutien limité aux parties prenantes non techniques
- L’observabilité de la production est limitée ; vous aurez donc besoin d’un autre outil pour la surveillance en direct.
La plateforme native de traçage, d’évaluation et de surveillance de LangChain avec des évaluateurs LLM en tant que juge et des métriques de récupération.
- Intégration optimale si votre pile s’exécute sur LangChain
- Capture automatique des traces, suivi des expériences, gestion des ensembles de données et versionnage des invites dans un seul tableau de bord
- La meilleure voie d’instrumentation pour l’instrumentation automatique est via LangChain.
- Les équipes indépendantes de tout framework perdent l’avantage du plug-and-play, car cela crée une dépendance vis-à-vis du framework.
Plateforme d’observabilité open source pour les applications LLM avec traçage, visualisation intégrée et diagnostics de récupération.
- L’intégration du clustering et de la détection de dérive vous aide à comprendre pourquoi la récupération a échoué.
- Les options d’auto-hébergement conviennent aux équipes ayant des exigences strictes en matière de résidence des données.
- Compatible avec tous les frameworks, notamment LangChain, LlamaIndex, et bien d’autres.
- Configuration manuelle des flux de travail d’évaluation
- Pas de simulation intégrée, généralement complétée par des ragas pour les mesures
Plateforme d’observabilité et d’évaluation de l’IA reliant les expériences hors ligne à la notation en production.
- Les mêmes scénaristes interviennent en développement et en production, il n’y a donc pas de décalage.
- Loop AI génère automatiquement de meilleures invites et des ensembles de données plus pertinents à partir des données de production
- Utilisé par Notion, Stripe et Cloudflare
- Non open source
- Spécialisé uniquement dans l’évaluation des LLM
Plateforme complète d’évaluation et d’observabilité de l’IA unifiant l’expérimentation, la simulation, l’évaluation et la surveillance de la production.
- La collaboration interfonctionnelle et les responsables de produits peuvent configurer les évaluations sans code
- Évaluation multiniveau (session, trace, étendue) pour un débogage précis
- Indépendant de tout cadre de référence
- Difficile à maîtriser pour les petites équipes qui n’ont besoin que de statistiques.
- Tarification axée sur les entreprises et communauté plus restreinte que Ragas ou LangSmith
Solution open source pour l’évaluation et le suivi des agents d’IA et des applications RAG. Utilise des fonctions de retour d’information pour évaluer la pertinence contextuelle, la cohérence et le réalisme.
- L’outil d’évaluation TruLens RAG fournit un tableau de bord des indicateurs permettant de comparer les versions d’applications.
- Traçage basé sur OpenTelemetry pour l’interopérabilité avec les piles existantes
- Communauté plus petite, mises à jour plus lentes que Ragas ou DeepEval
- Documentation insuffisante — intégration CI/CD limitée dès la sortie de la boîte
Plateforme d’ingénierie LLM open source offrant observabilité, gestion réactive et suivi des coûts. Auto-hébergeable via Docker ou Kubernetes.
- Contrôle total de l’auto-hébergement avec accès SQL pour le traçage des données et la création de rapports personnalisés
- Gestion rapide des versions et analyse des coûts incluses
- Les capacités d’évaluation sont plus rudimentaires que celles de Ragas ou de DeepEval.
- Davantage une couche de traçage qu’un cadre d’évaluation RAG complet
Comment choisir le bon outil pour votre équipe
Les listes de fonctionnalités sont inutiles sans contexte. Voici les 8 mêmes outils d’évaluation RAG associés aux profils d’acheteurs :
Évaluation de métriques open source : Ragas. Le framework d’évaluation le plus abouti pour RAG. Pour une approche pytest, utilisez DeepEval.
Ingénierie pilotée par les tests : l’évaluation RAG de DeepEval s’intègre nativement. Rédigez des assertions, exécutez-les dans l’intégration continue et contrôlez les demandes de fusion. Ajoutez Langfuse ou Phoenix pour le traçage.
Flux de travail utilisant intensivement LangChain : LangSmith. Ne luttez pas contre l’écosystème. Sachez simplement que changer de framework ultérieurement impliquera de réinstrumenter le tout.
Observabilité et débogage : Arize Phoenix pour les solutions open source auto-hébergées. Braintrust pour la gestion du scoring en production.
Boucles de rétroaction de production : Braintrust ou Maxim. Les deux systèmes bouclent la boucle depuis les défaillances de production jusqu’à la mise à jour des suites de tests.
Auto-hébergé / respectueux de la vie privée : Langfuse ou Phoenix. Les deux sont des solutions open source offrant un contrôle total des données.
Comparaison rapide :
Ragas
Score métrique
Fort
Non
Oui
ligne de base d’évaluation OSS
DeepEval
Développement piloté par les tests
Fort
Limité
Oui
pipelines CI/CD
LangSmith
Traçage de LangChain
Bien
Oui
Non
Piles LangChain
Phoenix
Observabilité
Basique
Oui
Oui
Débogage auto-hébergé
Braintrust
boucles d’évaluation de production
Bien
Oui
Non
Équipes d’IA de production
Maxim AI
Cycle de vie complet
Bien
Oui
Non
Transversal
TruLens
Comparaison des versions
Bien
Limité
Oui
Équipes basées à OTel
Langfuse
Traçage et opérations
Basique
Oui
Oui
Opérations auto-hébergées
Erreurs courantes des équipes lors de l’évaluation RAG
Nous avons constaté ces erreurs lors de dizaines de tests de LLM. Elles sont plus fréquentes qu’on ne le pense.
- Utilisez uniquement les scores de pertinence des réponses. Un score RAG élevé pour la pertinence des réponses est inutile si votre outil de recherche a extrait les mauvais documents. Évaluez toujours la recherche et la génération séparément.
- Omission de l’évaluation de la récupération. De nombreuses équipes se contentent de vérifier si la réponse est satisfaisante et négligent la question essentielle : le système a-t-il récupéré le contenu adéquat ? C’est l’une des principales lacunes des plateformes d’évaluation RAG.
- Se fier aveuglément à un seul modèle d’évaluation, c’est comme s’auto-corriger. Il est préférable d’utiliser plusieurs évaluateurs et de valider les processus critiques par une vérification humaine. Nous avons récemment abordé les risques cachés liés aux agents d’IA.
- Évaluation hors ligne uniquement. Votre jeu de données de test contient les requêtes que vous avez prévues. En production, il contient celles auxquelles vous ne vous attendiez pas. L’évaluation RAG nécessite un retour d’information en temps réel sur la production.
- Il n’existe aucun moyen de réintégrer les défaillances de production dans l’ensemble de données. Les équipes les plus performantes considèrent chaque mauvaise réponse comme un cas de test potentiel. Braintrust et Maxim automatisent ce processus. Les autres solutions nécessitent une intervention manuelle, et cette intervention manuelle n’est pas viable à grande échelle.
Voici à quoi ressemble une pile d’évaluation RAG pratique
Aucun outil RAG ne couvre à lui seul tous les besoins. Les équipes qui développent des applications LLM fiables ont tendance à combiner deux ou trois outils en une suite adaptée à leur niveau de maturité, leur budget et leur structure. Voici les trois configurations qui donnent les meilleurs résultats.
Pile logicielle open source allégée : Ragas + Phoenix ou Langfuse
Si vous êtes une jeune équipe développant un système RAG avancé avec un budget serré, cette solution vous offre l’essentiel sans frais de licence. Ragas gère les métriques de récupération et de génération, notamment la précision du contexte, la fidélité et la pertinence des réponses, tandis que Phoenix ou Langfuse ajoutent la couche de traçage et d’observabilité nécessaire pour déboguer les problèmes survenus en production. Phoenix et Langfuse prennent tous deux en charge l’auto-hébergement complet, vous permettant ainsi de conserver un contrôle total de vos données dès le premier jour.
Pile d’assurance qualité Code-First : DeepEval + CI/CD + Traçage
Pour les équipes d’ingénierie qui souhaitent que chaque pull request soit évaluée avant sa mise en production, DeepEval exécute des suites d’évaluations sous forme de tests pytest standard et s’intègre directement à GitHub Actions pour des contrôles qualité automatisés. Combiné à Langfuse pour la capture de traces, il offre un pipeline léger mais rigoureux qui détecte les régressions avant qu’elles n’atteignent les utilisateurs. C’est la solution que nous recommandons aux équipes qui recherchent des tests rigoureux pour leurs chatbots, copilotes et systèmes de recommandation, sans pour autant s’engager dans une plateforme de gestion lourde.
Pile technologique de production gérée : Braintrust, LangSmith ou Maxim
Lorsque votre application est déjà en production et que vous avez besoin de tableaux de bord, d’alertes et de comparaison d’expériences prêts à l’emploi, une plateforme managée s’avère pertinente. LangSmith est le choix idéal pour les équipes utilisant LangChain, grâce à son instrumentation automatique. Braintrust convient aux équipes privilégiant l’évaluation et souhaitant des systèmes d’évaluation identiques en développement et en production, avec une boucle claire reliant les échecs aux cas de test. Enfin, Maxim est particulièrement adapté aux organisations où les chefs de produit, et pas seulement les ingénieurs, participent à la définition et au suivi des normes de qualité.
Nous avons appliqué un raisonnement similaire lors des tests d’assurance qualité de Sitch, une application de mise en relation par IA où les recommandations devaient rester pertinentes malgré l’évolution rapide des données utilisateur.
Quel que soit le framework choisi, assurez-vous qu’il réponde aux questions suivantes : la recherche est-elle correcte ? La génération est-elle fidèle ? Le système s’améliore-t-il au fil du temps ? Si vos outils ne permettent pas de boucler la boucle, vous construisez sur du sable. Et si vous avez besoin d’aide pour configurer les tests de recherche et de recommandation par IA, nous accompagnons les équipes dans la conception de frameworks de test et de stratégies d’assurance qualité IA.
Pour conclure
Le meilleur outil d’évaluation RAG n’est pas celui qui possède la plus longue liste de métriques. C’est celui qui correspond à votre flux de travail et qui vous permet de passer de l’échec à l’amélioration.
Commencez par mesurer séparément la récupération et la génération. Automatisez autant que possible dans votre processus CI/CD. Surveillez la production dès le premier jour. Et considérez chaque réponse anormale comme un signal d’alarme pour améliorer votre système.
Les outils sont là. Le véritable facteur de différenciation réside dans la rapidité avec laquelle votre équipe peut passer de « cette réponse était erronée » à « cet échec est désormais un cas de test ». Choisissez la solution qui raccourcit le cycle, et si vous avez besoin d’aide, n’hésitez pas à contacter notre équipe.
FAQ
Quel est l’outil d’évaluation RAG le plus populaire ?
Ragas est l’option open source la plus répandue et l’outil d’évaluation RAG le plus populaire dans les benchmarks académiques. Pour les plateformes gérées, LangSmith et Braintrust sont les solutions de référence en production.
Quelle est la différence entre l’évaluation RAG et l’évaluation LLM standard ?
L’évaluation standard LLM vérifie la qualité des résultats. L’évaluation RAG ajoute des métriques spécifiques à la recherche : le système a-t-il extrait les bons documents et la génération leur est-elle restée fidèle ?
Puis-je utiliser plusieurs outils d’évaluation RAG simultanément ?
Oui. On utilise généralement Ragas ou DeepEval pour les métriques, et Phoenix ou Langfuse pour le traçage. L’écosystème des outils et modèles d’évaluation Ragas est conçu pour être modulaire.
Qu’est-ce que l’outil d’évaluation ARES RAG ?
L’outil d’évaluation ARES RAG teste la robustesse de la récupération avec des exemples adverses. Utile pour les tests de robustesse, il est moins courant en production que Ragas ou DeepEval.
Comment évaluer RAG sans étiquettes de vérité terrain ?
Utilisez des métriques sans référence. Ragas et DeepEval prennent tous deux en charge l’évaluation de la fidélité et de la pertinence par un juge, selon le modèle LLM, sans réponses prédéfinies. Ragas a été le premier à proposer cette approche pour l’évaluation RAG sans étiquette.
Que comprend une évaluation des risques RAG ?
Une évaluation des risques RAG analyse la qualité des données, la couverture de la récupération, les taux d’erreurs et les risques de non-conformité. Combinez la notation automatisée à l’analyse d’experts pour détecter les problèmes que les indicateurs seuls ne permettent pas d’identifier.

